
 ×
×

Carlos Libardo.
AI engineer · founder
- Voltbras · founder & CTO · 2018 LatAm's first EV charging platform. 7 countries. 15M BRL raised. Led 15+ engineers.
- Shippit · founder · today AI-native consultancy. Production agent systems.
- Gallium · founding AI engineer Multi-agent brain behind on-brand content generation. Automated quality scoring.
- Way2 Technology · AI consultant Agent orchestration inside one of Brazil's largest energy-sector platforms.
Agent orchestration · RAG · LLM-as-judge · Durable workflows · DDD · Clean Architecture · TDD
- Spec & failing test — the guardrail AI can't fake
- Subagents + worktrees — 4 min, not 16
- Live bake-off — 4 frameworks, 1 prompt, 1 merges
- Skills + MCP — brain & hands, same loop any IDE
- Receipts — tx hash, not a demo
My phone shipped a smart contract while I was asleep..
Base mainnet. 04:17 BRT. Receipt in eight minutes.
One prompt in.
A team of agents out..
AI took over the code. Next: agents take over the prompting.
Carlos Libardo · Shippit · 25 minutes · works with any AI coding CLI.
The spec is the guardrail..
Same prompt. Three modes. Three worktrees. Models fill ambiguity with confident guesses — the spec removes it, the failing test pins it.
→ The prompt (identical for all three)
add reply-rate by hour of day to campaign analyticsExecute mode
Agent codes immediately. No plan, no spec.
What you get
A chart on the page. Looks right. Metric is silently wrong — numerator and denominator count different events.
134 lines · 0 tests · 18 min
Gain: fastest to something on screen.
Cost: slowest to correct. No test catches the bug. No reviewer catches it. Ships Monday, dies Wednesday.
Plan mode
Agent proposes a plan in chat. You approve, then it codes.
What you get
Happy path is correct. Timezone chain handled. Edge cases you didn't think to name fall back to defaults — and you'll never know.
426 lines · 2 tests · 6 min
Gain: right thinking, right shape, atomic commits.
Cost: plan is prose, not an executable contract. No failing test pins behavior. Save-to-disk is opt-in — default lives in chat.
SDD + superpowers
Brainstorm → spec → plan → failing tests → green. On disk.
What you get
A spec that names the bug from card 1 — in plain English — before any code runs. Edge cases enumerated. Commits link back to acceptance criteria.
779 lines · 10 tests · 8 min
Gain: a durable contract the next agent or human can ship against in 6 months.
Cost: 6× the artifact. Overkill if you're throwing it away.
8 min vs 18. Discipline shipped faster than execute. Execute pays its tax mid-flight — in debug loops.
Failing test first.
Always..
// step 1 — agent commits a failing test
test("rejects expired session cookie", async () => {
const res = await app.request("/api/me", {
headers: { cookie: `sid=${expiredSid}` },
});
expect(res.status).toBe(401);
});
// → FAIL: received 200
// step 2 — agent fixes implementation
- const session = await db.get("sessions", sid);
+ const session = await db.get("sessions", sid);
+ if (!session || session.expiresAt < Date.now()) return c.json({}, 401);
// step 3 — green. atomic commit.
$ git log -1 --oneline
3f9a1c2 fix(auth): reject expired session cookieRed proves the prompt was understood. Green proves it's done.
Skills are the new function calls..
---
name: brainstorming
description: Use before any creative work —
features, components, functionality.
Explores intent and design first.
---
# Brainstorming Ideas Into Designs
1. Explore project context
2. Ask clarifying questions
3. Propose 2-3 approaches w/ trade-offs
4. Present design, get approval
5. Write spec → invoke writing-plansLazy-loaded catalog
Agent indexes descriptions. Pulls bodies only on match. 200+ workflows. Zero context bloat.
Source: superpowers:brainstorming — scoped this deck.
Anatomy
- Frontmatter = always-loaded one-liner. Routing layer.
- Body = procedure, fetched on match.
references/= even lazier — loaded only if body asks.
4 minutes, not 16..
Map a 200k-line repo. One conductor fans out 4 specialists. Synthesize once.
codebase map · deps scan · history read · extern search → RESEARCH.md
Pay for the slowest agent, not the sum.
Subagents.
Or agent teams..
Subagents · Task tool
Main agent spawns N helpers. Each gets a prompt. Each runs in isolation. Each reports back. No cross-talk.
Best for: focused lookups, code search, structured reports. Lower token cost.
Agent Teams · Claude Code v2.1.32+
Independent Claude instances. Shared task list. Teammates message each other directly. Lead synthesizes.
Best for: parallel review, competing hypotheses, cross-layer refactors. Higher token cost.
# Subagents — main agent calls Task tool, gets summaries back.
# Agent Teams — flip the flag, then ask the lead to spawn a team.
$ export CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1
$ claude
> Create a team of 3 reviewers for PR #142: security,
performance, test coverage. Have them debate findings.Subagents = MapReduce. Agent Teams = a small crew that argues. Same physics, different tokens. Docs: code.claude.com/docs/en/agent-teams.
One repo.
Three agents. Boom..
Without worktrees
With worktrees
Same physics as threads sharing memory. Need isolation.
git worktree add ../agent-a feature/sdd-mode
git worktree add ../agent-b feature/tdd-mode
git worktree add ../agent-c feature/yolo-modeSame repo, N filesystems. Merge later, in one place. No worktree, no parallel.
The browser is the final gate..
$ bun test:e2e tests/grant-submission.spec.ts
✓ submits proposal and routes to /pending 1.8s
✓ judge agent scores within 90s 62.3s
✓ score persists to base-sepolia 9.1s
✓ score reads back from on-chain 3.4s
4 passed (76.6s)
# agent reads the green output, marks task complete,
# opens PR. no human in the verify loop.Playwright
playwright.dev — scripted, deterministic E2E. You author selectors, actions, assertions; CI runs the suite headless. The bun test:e2e harness above is Playwright. The contract the agent must satisfy before merge.
agent-browser
agent-browser.dev — Vercel Labs CLI that hands the live browser to an agent. No script — the agent reasons step-by-step. Use to validate flows that don't have a spec yet, or to author the Playwright test from a recorded session.
Playwright = the gate. agent-browser = how the agent walks up to it. Type-checks lie. Unit tests lie. On-chain assertions don't.
Four frameworks.
One physics..
| Framework | Pick when… | Skip if… | Killer move |
|---|---|---|---|
| Superpowers ★ | You want the agent to run itself — brainstorm → design → TDD → ship — gated. | One-shot edits or exploratory hacking. | Hard gate: no code until design is approved, then subagents execute the plan autonomously. |
| GSD | Long-running AI work where context rot would kill quality. | Throwaway prototypes with no follow-up. | Fresh-context subagents per role — main window stays clean. |
| OpenSpec | You want AI to commit to a spec before guessing at code. | You don't want spec artifacts in your repo. | Per-change folder — proposal + spec + tasks — archived into history. |
| Spec Kit | You want spec-as-contract portable across any AI CLI. | You want speed over ceremony. | constitution → specify → clarify → plan → tasks → implement. |
★ = my personal pick after months of daily use. Don't take my word for it — clone one tonight, run it on a real ticket, feel the difference. The patterns travel; the CLI doesn't matter. Your repo, your call.
Same product. Four runs.
One merged to main..
| Branch | Framework | Commits | Files | LOC | Tests | Coverage | Outcome |
|---|---|---|---|---|---|---|---|
speckit |
Spec Kit | 35 | 254 | 29K | ~280 (78 E2E) | n/a | Deployed · closed |
full-vision-roadmap |
GSD | 97 | 1,098 | 181K | ~1,500 | n/a | Deployed · closed |
superpower |
Superpowers | 66 | 987 | 197K | ~1,440 | n/a | Deployed · closed |
ralph-unified ★ |
Ralph Loop | 17 | 117 | 13.8K | 570 | 93.66% | Merged to main |
Read the numbers
GSD & Superpowers generated 13×–14× the code of the winner (181K & 197K LOC). Both deployed; neither merged. Spec Kit stayed compact (29K) but lighter on tests. Ralph-unified shipped 13.8K LOC, 570 tests, and the only measured coverage (93.66%) — merged to main.
Ralph Loop
Huntley pattern: while :; do claude -p "@PROMPT.md"; done. Same prompt re-fed until criteria met. Used here to review the three branches and compile the best of each. Honest receipt: crashed mid-loop many times, needed manual restarts — but the only branch I trusted on main.
The agent audited its own contracts..
Same agent. Same loop. 4 audit skills, run on every PR.
6 contracts shipped to Base. Identical bytecode on Sepolia. Audit findings fixed before merge — Solidity 0.8.24, Foundry.
Every evaluation → a tx hash users can click..
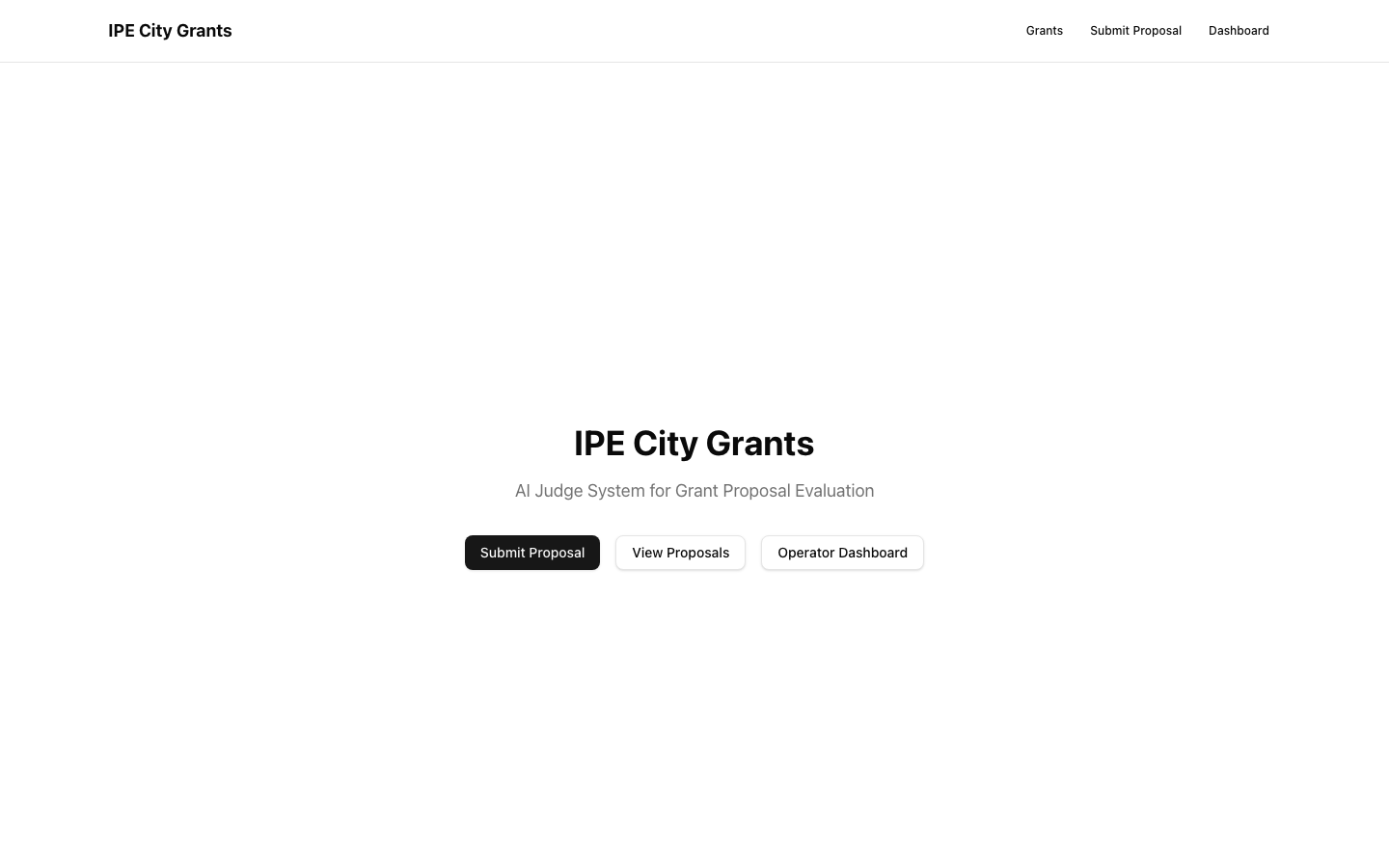
Three doors
Submit · View · Operator. Same shape across all 3 framework branches.
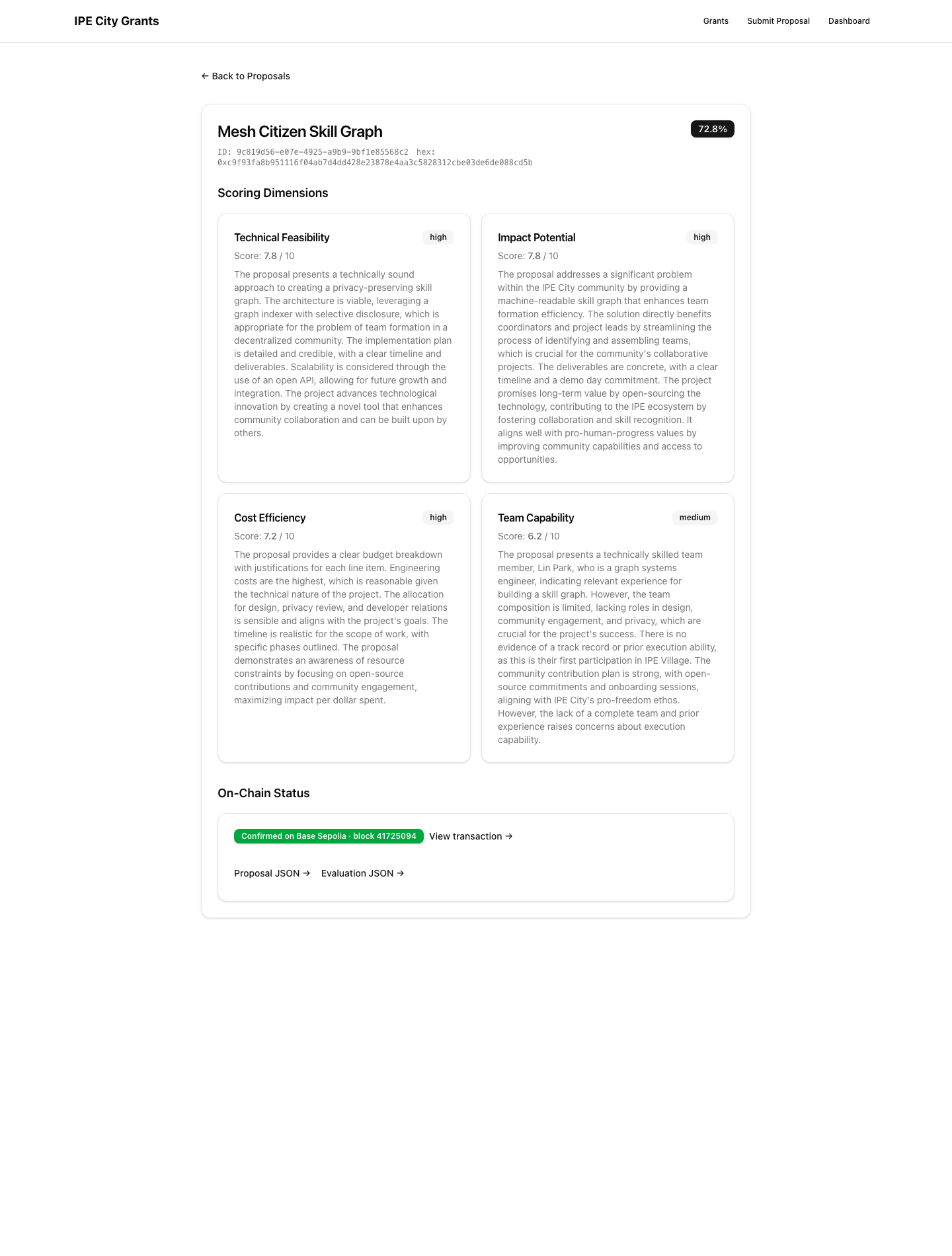
The receipt
AI scores → tx hash → Basescan. Clickable on the card.
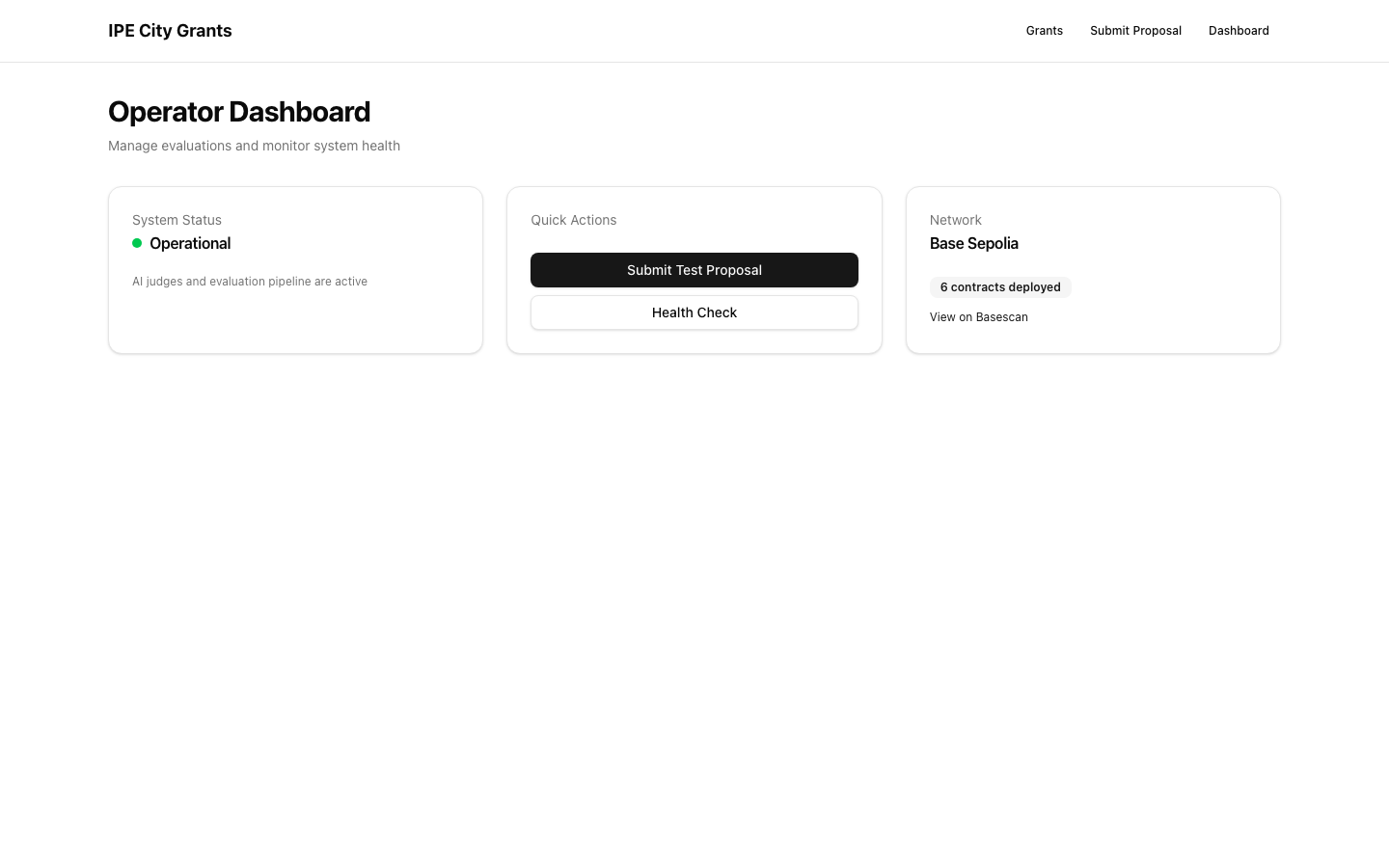
The proof
Operational · Base Sepolia · 6 contracts. All on Basescan.
agent-reviewer-ralph.run.app — open mid-demo, click any tx.
One weekend.
V0 in production..
Stack — boring on purpose
Team LinkedIn outreach. Each teammate's account, their voice — agents research leads, write the message, time the follow-up.
Spec first. Failing test second. Agent third. Sleep fourth.
specs/Every teammate, their own agent..
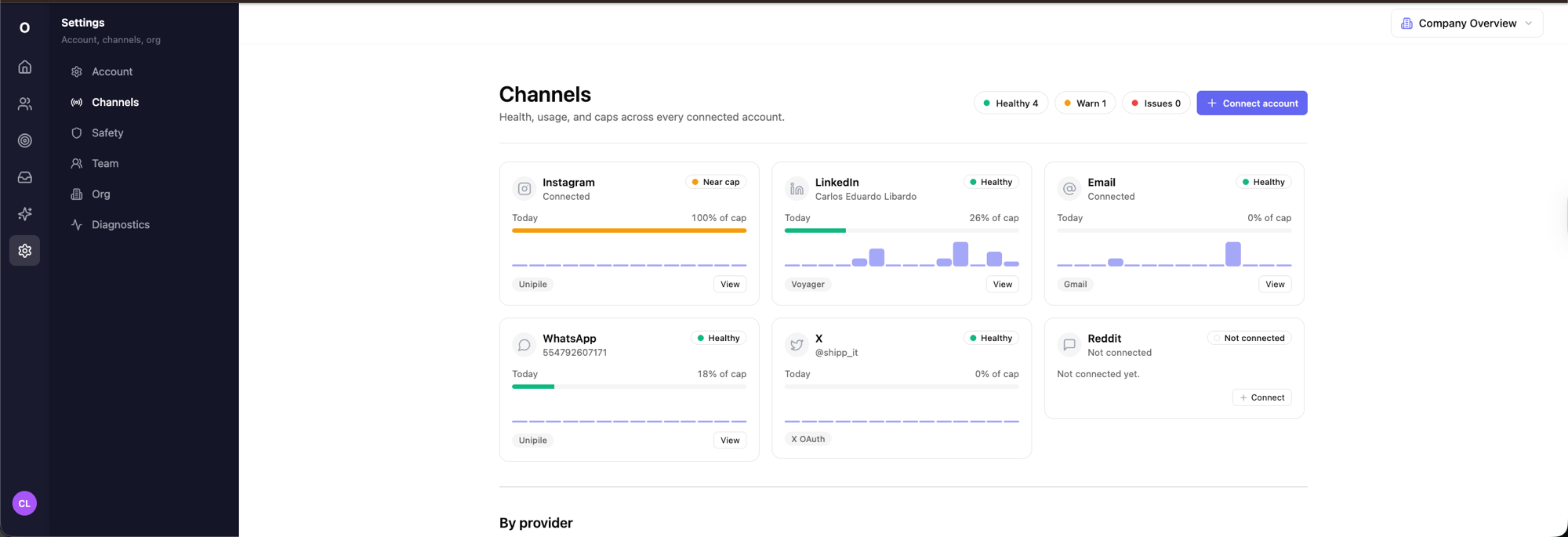
Channels · health + caps
6 channels, one cockpit. Instagram, LinkedIn, Email, WhatsApp, X, Reddit. Per-account daily cap, warmup curve, healthy / near-cap / issues at a glance.
Each provider (Unipile, Voyager, Gmail, X OAuth) abstracted away. The rep sees one safety surface, not six dashboards.
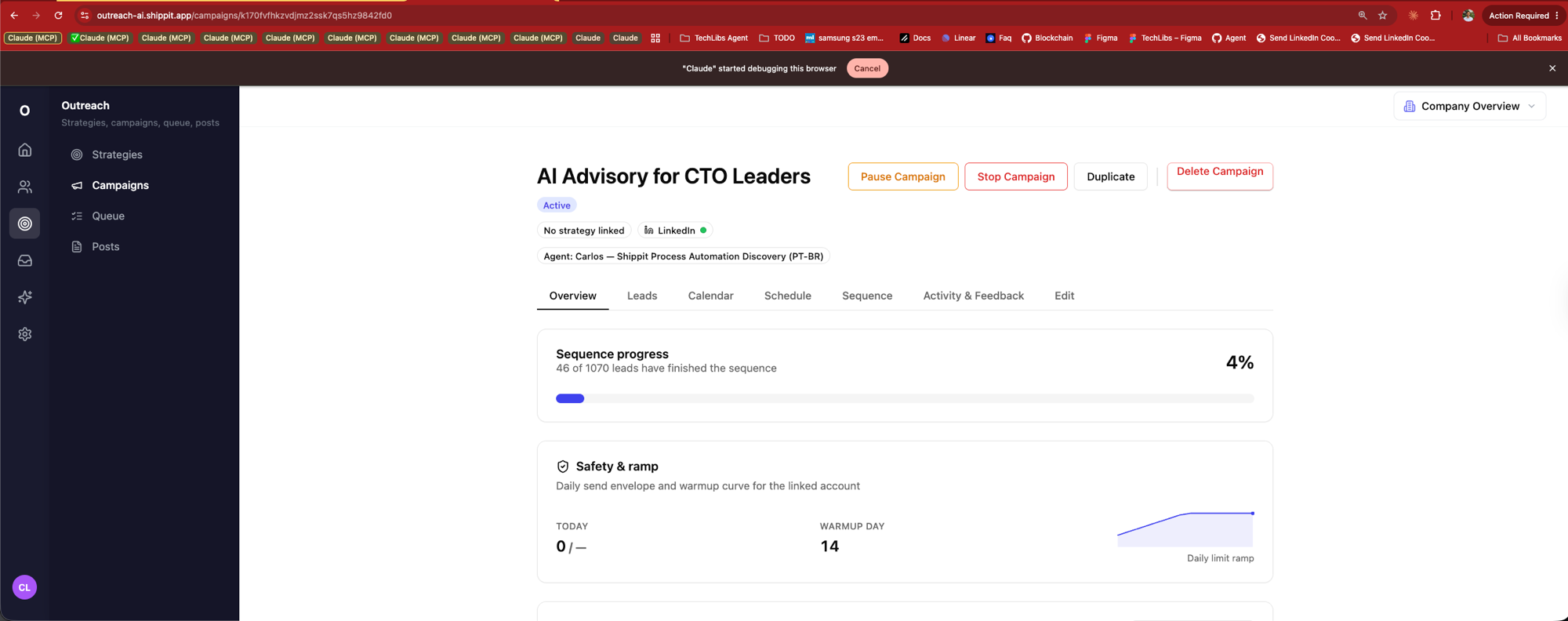
Campaign · sequence + ramp
AI Advisory for CTO Leaders. 46 of 1070 leads through the sequence. Safety ramp, warmup day 14, daily limit curve — every send auditable.
A campaign = strategy (ICP × agent × sequence × channel) replayed against a lead list. Pausable mid-flight without breaking the others.
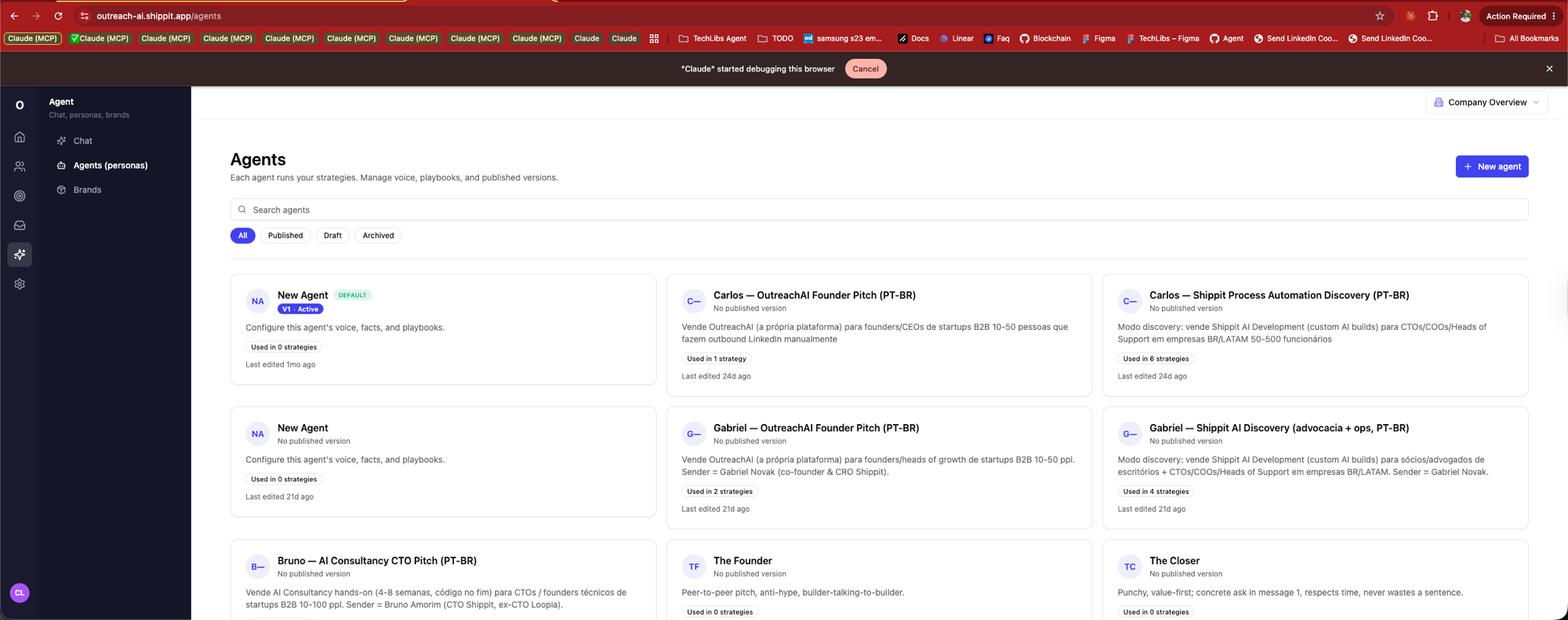
Agents · voice + playbooks
Carlos — Founder Pitch. Gabriel — Shippit Discovery. Bruno — AI Consultancy CTO. Each teammate has a versioned agent: voice, facts, playbook.
The agent doesn't replace the rep — it is the rep, in delegated form. Voice survives. Authenticity isn't lost in templating.
Brand as code.
Three ways in..
/gsp · get shit pretty
Brand contract in markdown — tokens, voice, banned words, layout grammar. Same agent that ships code ships on-brand UI.
- How: skills +
STYLE.md+ tokens gate every PR - Banned-words filter, token diff in PR body
- Generative: deck, site, app compile from one contract
- OSS ·
jubscodes/get-shit-pretty· gsp.jubs.studio
Claude Design · Anthropic Labs
Iterative design agent with a few tricks up its sleeve. Reach for it if you like the Claude app aesthetic.
- How: Tailwind v4 tokens + dark-first React components, agent iterates on the surface
- Production-tested by the Claude Code team
- Fork, repaint with your own token layer (e.g. /gsp)
- Tell: strong embedded DNA — after a few runs you'll see the Claude-app fingerprint in the initial outputs.
anthropic.com/news/claude-design
Figma MCP · designs as context
MCP server bridges Figma into the agent. Pull frames, variables, components directly into code-gen prompts.
- How: agent calls
get_code/get_imageon a selection - Variables → CSS tokens, auto-layout → flex / grid
- Pixel-true handoff without screenshot prompts
figma.com/dev-mode-mcp
| Tool | Form | Owns | Reach for when… |
|---|---|---|---|
| /gsp | Markdown contract + skills | Brand identity, voice, generative output | You want one source of truth across deck, app, docs. |
| Claude Design | Iterative design agent + React components | AI-native UI primitives | You like the Claude app look — heads-up, its DNA bleeds into the initial outputs. |
| Figma MCP | MCP server | Pixel-true handoff | Designers already finalized screens in Figma. |
Skills load lazy.
CLAUDE.md is always there..
Both are just markdown. Difference is when they load.
Static prompt — CLAUDE.md / AGENTS.md
Loaded once at session start. Always in context. Costs tokens every turn. Use for rules that apply always: stack, conventions, hard constraints, identity.
- Project root → every session reads it
- Bloat = context tax on every reply
- Keep tight: who you are, what not to do
Dynamic capability — Skills
Frontmatter (name + description) sits in a one-line index. Body only loads when the description matches the task — or you type /skill-name.
- 200+ skills can sit dormant, ~0 cost
- Agent reads YAML → decides → loads
SKILL.md references/= even lazier (loaded only if body says so)- Docs:
code.claude.com/docs/en/skills
Progressive disclosure. Static prompt = identity. Skills = procedures the agent fetches when it needs them.
Correct it once.
It stops happening..
The loop
A self-improvement skill watches for corrections. Classifies them. Writes the lesson to the right file — silently. Next session reads it back.
- Reactive — user corrects → log lesson
- Proactive — session start → read lessons → apply
- Analytical — "what did you learn" → review + table
Triage — where the lesson lands
| File | For |
|---|---|
.self-improvement/lessons.md | project-specific mistakes |
KNOWLEDGE.md | cross-project platform gotchas |
CLAUDE.md | permanent rules / conventions |
Real example: Oracle on Apple Silicon needs Colima, not Docker Desktop. Captured once in KNOWLEDGE.md → every future session avoids the 2-hour rabbit hole.
Skills that update memory. Memory that feeds skills. Agent gets sharper per session — not per training run.
Skills travel.
And they plug in..
Travel — same SKILL.md, different IDE
Frontmatter (name + description) is the contract. The body is markdown. One file ships unchanged on Claude Code · Cursor · Replit · Lovable.
- Lovable ·
docs.lovable.dev/features/skills— workspace-scoped, ZIP-portable - Replit ·
.agents/skills/— same frontmatter shape - Bolt / v0 / Volt —
AGENTS.mdat repo root as the global slot
Plug in — MCP · API key · /chrome
Skills are the brain. MCP is the hands. Three rungs to reach anything.
- MCP ·
modelcontextprotocol/servers— Gmail, Slack, Linear, Stripe, Postgres as typed actions - API key in
.env— skill calls REST when no MCP yet /chromeMCP — drives a real browser when there's no API at all
Three rungs, zero dead ends. Native MCP first, REST with a key second, browser-driving third. If a human can reach it, the agent can.
Your agent stops
hallucinating ABIs..
| Resource | What it gives you |
|---|---|
ethskills.com |
24 markdown skills · corrects stale ETH training data |
OpenZeppelin/openzeppelin-skills |
Contract patterns from the OG · battle-tested |
OpenZeppelin/openzeppelin-mcp |
Natural language → contract scaffold via MCP |
coinbase/agentkit |
Agent → onchain actions · any framework |
trailofbits/skills |
Trail of Bits audit shelf · vulnerability detection + workflows |
auditmos/skills |
audit-signature · audit-liquidation-dos · audit-external-call · audit-arithmetic |
| The 4 we ran on ipê-city | |
solidity-security |
Reentrancy · access control · overflow · delegatecall — block merge on finding |
solidity-gas-optimization |
80+ RareSkills patterns · storage packing · calldata · short-circuit |
secrets-scanner |
Leaked keys / tokens in .env, fixtures, deploy scripts · pre-commit gate |
dependency-supply-chain-security |
npm audit · vulnerable / typosquatted packages · Foundry lib pinning |
Same shape as the shelf we used to audit ipê-city. Drop the folder in, the agent reads the skills, ABI hallucinations stop.
Same loop.
Different paint..
| Framework | Sweet spot | Tradeoff |
|---|---|---|
Claude Agent SDK · direct |
Thin layer over the model · max control · ships with Claude Code primitives | You wire orchestration · no batteries |
LangChain / LangGraph |
Biggest ecosystem · graph-based control flow · every provider | Heavy abstraction · churny API |
mastra.ai |
TS-first · agents + workflows + evals + memory in one stack · Vercel-native | Young · Node-only |
CrewAI |
Role-based crews · fastest path to multi-agent demo · Python | Less control · opinionated |
Agno |
Python · multimodal-first · perf-tuned · lean runtime | Smaller community |
Orchestration is a slot. Pick the dialect that matches your runtime — the loop underneath is the one we walked through tonight.
Three dials.
Or your $40 becomes $400..
Model split
Opus plans & reviews. Sonnet executes. ~5× cost gap, ~0× quality gap if the plan is good.
Context budget
/compact on long sessions. CLAUDE.md for state worth keeping. New chat when the cache window slips past 5 minutes — token cost cliff, not a curve.
Cost is a knob, not a verdict. Tune the split, isolate the checkouts, compress the chatter — same output, fraction of the spend.
Steal everything.
Then ask AI for more..
The pillars · disciplines underneath the dialects
| Framework / skill | Where to get it |
|---|---|
| Spec Kit | github.com/github/spec-kit |
| Superpowers | github.com/obra/superpowers · npx superpowers init |
| GSD | gsd-build/get-shit-done · gsd-2 · gsd-1 · npx gsd-pi |
| OpenSpec | github.com/Fission-AI/OpenSpec |
| /gsp — get shit pretty | jubscodes/get-shit-pretty · gsp.jubs.studio · npx get-shit-pretty |
| Simply Shippit | shippit.app · coming soon (internal use only) — keep in touch |
This is a startkit.
Anything not on this slide — your agent can find a fitter alternative in one prompt. The shelf is infinite. Ask for the skill that matches your stack.
Remove me as the
bottleneck..
One person can only sit in front of one Claude Code session at a time. That's the ceiling.
vlad-cockpit is the orchestration layer I'm building on top of Claude Code — so many agents can work in parallel, in different repos, while I review instead of type.
Still early. Rough edges everywhere. Sharing the direction, not the polish.
The shift
- From: me typing prompts, one at a time
- To: me reviewing work from a fleet of agents
- Trigger: a schedule, a GitHub issue, a webhook — not me
- I unblock when something needs judgment. The rest runs.
Four wins, even half-built..
One screen, every agent
Every session in flight, on one page. Status, what it's working on, when it last moved. No tab-juggling, no "where did that one go".
Cost X-ray
Spend per project, per model, per session. Find the leak before it bleeds. Decide which agents earn their keep.
Scheduled agents
"Audit dependencies every Monday at 7am." Set it, walk away. Work happens whether I'm at the keyboard or not.
Phone-first access
Same cockpit on phone, laptop, tablet. Approve, take over, or walk away — from anywhere. Push notifications when an agent needs a human.
A dozen agents. One pane of glass..
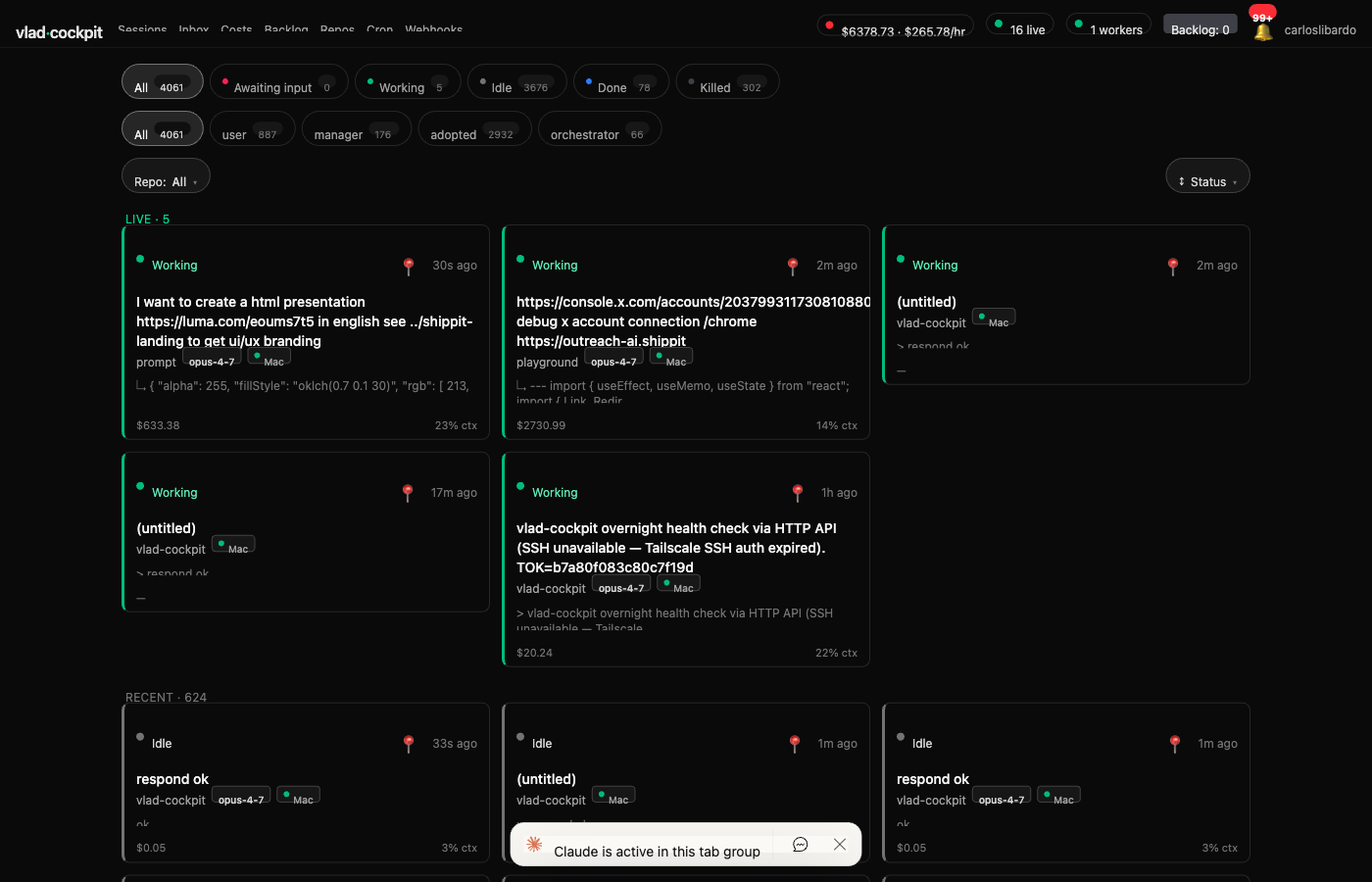
Every agent at a glance
A dozen agents working in parallel — across different projects. One card each: what it's doing, how long it's been at it, how much it's spent.
Triage takes 5 seconds, not 5 minutes. Tap a card to drop in.
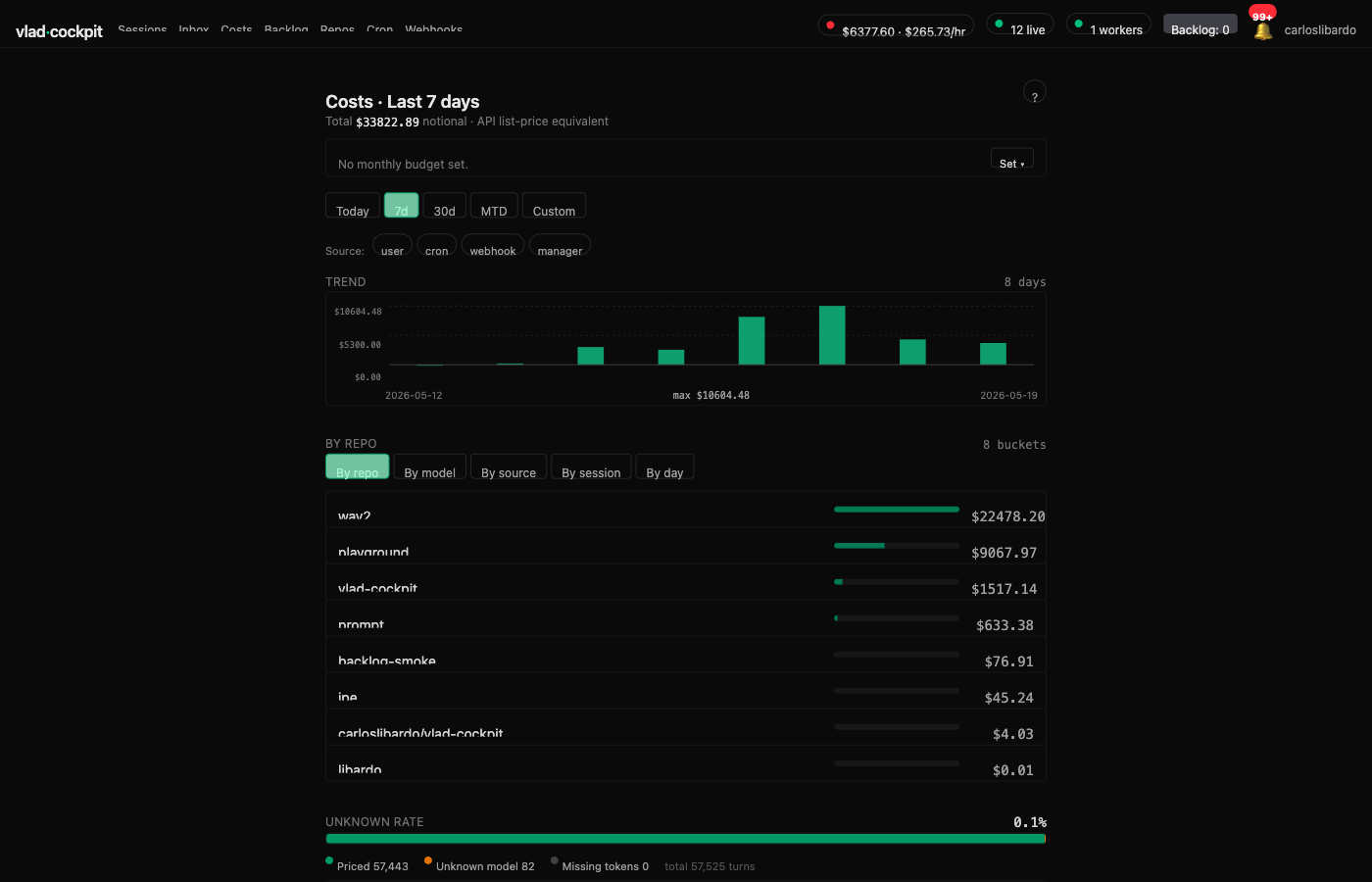
Where the money went
Spend broken down by project, model, and session — over the last 7 days. The big consumer, the cheap experiment, the runaway.
No more "I think it cost about…". You see it. You decide.
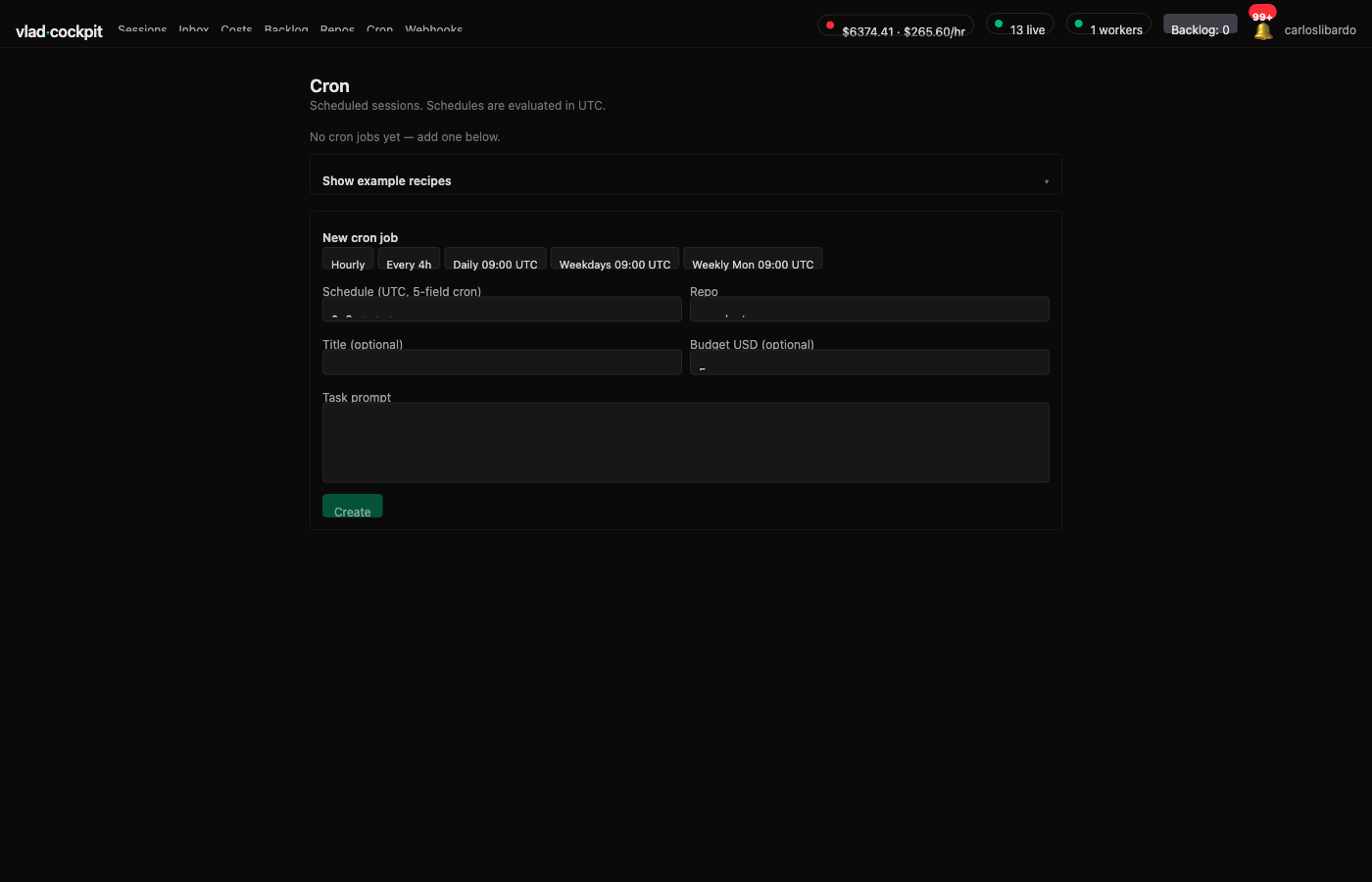
Agents that fire themselves
Pick a project, a budget, a prompt, and a cadence — hourly, daily, weekly. The agent runs without me remembering to start it.
Recurring work stops depending on my memory.
Four verbs. GitHub keeps score..
What the other SDD frameworks don't solve
- Team coordination. Most SDD assumes one dev. Simply Shippit treats milestone = feature, issue = AC, PR closes the loop.
- AC traceability. Every test, every review, every commit links back to the issue's acceptance criteria. No drift.
- The CHECK layer. "Tasks done" ≠ "goals met."
/shippit:checkruns verify-before-shipping with evidence. - Session rituals.
/shippit:gm&/shippit:gnsync state with GitHub each day, across the team.
Pipeline
/shippit:plan → scan · research · propose
/shippit:build → implement · test
/shippit:check → review · verify
/shippit:ship → verify · test · commit · pr
22 skills · 7 agents · GitHub-native state. Plugin for Claude Code. M1 dropping soon.
Open the laptop.
Ship tonight..
You're one prompt away from whatever you want to build. The tools exist. The patterns exist. The only variable left is whether you open the laptop tonight.
Ship the receipt,
not the demo..

Scan or visit
techlibs.github.io/
prompt-night/deck/
Carlos Libardo · Shippit
shippit.app · luma.com/eoums7t5
Questions in the open. Builder track at the back.